 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFisher-Preserving Guidance: Training-Free Manifold Constraints for Safe Diffusion Control
May 28, 2026Diffusion models are effective for waypoint prediction in visual navigation, but standard sampling and test time guidance can produce unreliable or inefficient trajectories when updates drift off the training manifold. We propose Fisher Preserving Guidance with Outer Product Span Projection, a training-free inference method that avoids large Fisher drift associated with off-distribution actions while optimizing a task objective. Our method computes the Fisher-preserving update via a low-rank Jacobian factorization, requiring only a single backward pass per step and enabling real-time use. We further introduce Truncated Fisher Denoising Sensitivity as an uncertainty signal and use it for robust multi-sample action blending. Experiments on toy and realistic navigation benchmarks, including Maze2D with TSDF-based guidance, PushT with official Diffusion Policy weights, and visual navigation in simulation and on real robots, demonstrate consistent improvements in performance over strong diffusion-policy baselines without additional training.
Learning Reference-Guided Exposure Correction with Hybrid Illumination Characteristics
May 26, 2026We present HICNet, a reference-guided exposure correction framework. A lightweight, content-agnostic encoder distills each image into a compact illumination embedding capturing regional brightness, edge contrast, and higher-order luminance moments. The embedding difference between a source and its reference drives a multi-scale modulation network that combines FiLM-based global adjustment with Photometric Channel Rebalancing for fine-grained, illumination-aware spectral gating, producing exposure-matched outputs while faithfully preserving scene details. A cross-batch contrastive loss orders the illumination manifold, bolstering robustness to diverse lighting conditions. Trained without ground truth or intrinsic decomposition, HICNet attains better accuracy on public benchmarks and generalizes well to entirely unseen scenes.
STRNet: Visual Navigation with Spatio-Temporal Representation through Dynamic Graph Aggregation
Apr 03, 2026Visual navigation requires the robot to reach a specified goal such as an image, based on a sequence of first-person visual observations. While recent learning-based approaches have made significant progress, they often focus on improving policy heads or decision strategies while relying on simplistic feature encoders and temporal pooling to represent visual input. This leads to the loss of fine-grained spatial and temporal structure, ultimately limiting accurate action prediction and progress estimation. In this paper, we propose a unified spatio-temporal representation framework that enhances visual encoding for robotic navigation. Our approach extracts features from both image sequences and goal observations, and fuses them using the designed spatio-temporal fusion module. This module performs spatial graph reasoning within each frame and models temporal dynamics using a hybrid temporal shift module combined with multi-resolution difference-aware convolution. Experimental results demonstrate that our approach consistently improves navigation performance and offers a generalizable visual backbone for goal-conditioned control. Code is available at \href{https://github.com/hren20/STRNet}{https://github.com/hren20/STRNet}.
Large language models for spreading dynamics in complex systems
Feb 08, 2026Spreading dynamics is a central topic in the physics of complex systems and network science, providing a unified framework for understanding how information, behaviors, and diseases propagate through interactions among system units. In many propagation contexts, spreading processes are influenced by multiple interacting factors, such as information expression patterns, cultural contexts, living environments, cognitive preferences, and public policies, which are difficult to incorporate directly into classical modeling frameworks. Recently, large language models (LLMs) have exhibited strong capabilities in natural language understanding, reasoning, and generation, enabling explicit perception of semantic content and contextual cues in spreading processes, thereby supporting the analysis of the different influencing factors. Beyond serving as external analytical tools, LLMs can also act as interactive agents embedded in propagation systems, potentially influencing spreading pathways and feedback structures. Consequently, the roles and impacts of LLMs on spreading dynamics have become an active and rapidly growing research area across multiple research disciplines. This review provides a comprehensive overview of recent advances in applying LLMs to the study of spreading dynamics across two representative domains: digital epidemics, such as misinformation and rumors, and biological epidemics, including infectious disease outbreaks. We first examine the foundations of epidemic modeling from a complex-systems perspective and discuss how LLM-based approaches relate to traditional frameworks. We then systematically review recent studies from three key perspectives, which are epidemic modeling, epidemic detection and surveillance, and epidemic prediction and management, to clarify how LLMs enhance these areas. Finally, open challenges and potential research directions are discussed.
SpectralAdapt: Semi-Supervised Domain Adaptation with Spectral Priors for Human-Centered Hyperspectral Image Reconstruction
Nov 17, 2025Hyperspectral imaging (HSI) holds great potential for healthcare due to its rich spectral information. However, acquiring HSI data remains costly and technically demanding. Hyperspectral image reconstruction offers a practical solution by recovering HSI data from accessible modalities, such as RGB. While general domain datasets are abundant, the scarcity of human HSI data limits progress in medical applications. To tackle this, we propose SpectralAdapt, a semi-supervised domain adaptation (SSDA) framework that bridges the domain gap between general and human-centered HSI datasets. To fully exploit limited labels and abundant unlabeled data, we enhance spectral reasoning by introducing Spectral Density Masking (SDM), which adaptively masks RGB channels based on their spectral complexity, encouraging recovery of informative regions from complementary cues during consistency training. Furthermore, we introduce Spectral Endmember Representation Alignment (SERA), which derives physically interpretable endmembers from valuable labeled pixels and employs them as domain-invariant anchors to guide unlabeled predictions, with momentum updates ensuring adaptability and stability. These components are seamlessly integrated into SpectralAdapt, a spectral prior-guided framework that effectively mitigates domain shift, spectral degradation, and data scarcity in HSI reconstruction. Experiments on benchmark datasets demonstrate consistent improvements in spectral fidelity, cross-domain generalization, and training stability, highlighting the promise of SSDA as an efficient solution for hyperspectral imaging in healthcare.
WGRAMMAR: Leverage Prior Knowledge to Accelerate Structured Decoding
Jul 22, 2025Structured decoding enables large language models (LLMs) to generate outputs in formats required by downstream systems, such as HTML or JSON. However, existing methods suffer from efficiency bottlenecks due to grammar compilation, state tracking, and mask creation. We observe that many real-world tasks embed strong prior knowledge about output structure. Leveraging this, we propose a decomposition of constraints into static and dynamic components -- precompiling static structures offline and instantiating dynamic arguments at runtime using grammar snippets. Instead of relying on pushdown automata, we employ a compositional set of operators to model regular formats, achieving lower transition latency. We introduce wgrammar, a lightweight decoding engine that integrates domain-aware simplification, constraint decomposition, and mask caching, achieving up to 250x speedup over existing systems. wgrammar's source code is publicly available at https://github.com/wrran/wgrammar.
RAPID Hand: A Robust, Affordable, Perception-Integrated, Dexterous Manipulation Platform for Generalist Robot Autonomy
Jun 09, 2025
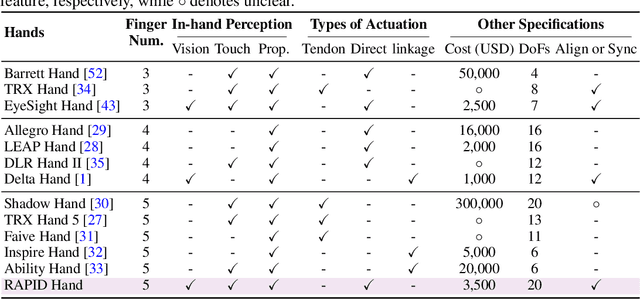


This paper addresses the scarcity of low-cost but high-dexterity platforms for collecting real-world multi-fingered robot manipulation data towards generalist robot autonomy. To achieve it, we propose the RAPID Hand, a co-optimized hardware and software platform where the compact 20-DoF hand, robust whole-hand perception, and high-DoF teleoperation interface are jointly designed. Specifically, RAPID Hand adopts a compact and practical hand ontology and a hardware-level perception framework that stably integrates wrist-mounted vision, fingertip tactile sensing, and proprioception with sub-7 ms latency and spatial alignment. Collecting high-quality demonstrations on high-DoF hands is challenging, as existing teleoperation methods struggle with precision and stability on complex multi-fingered systems. We address this by co-optimizing hand design, perception integration, and teleoperation interface through a universal actuation scheme, custom perception electronics, and two retargeting constraints. We evaluate the platform's hardware, perception, and teleoperation interface. Training a diffusion policy on collected data shows superior performance over prior works, validating the system's capability for reliable, high-quality data collection. The platform is constructed from low-cost and off-the-shelf components and will be made public to ensure reproducibility and ease of adoption.
GET: Goal-directed Exploration and Targeting for Large-Scale Unknown Environments
May 28, 2025Object search in large-scale, unstructured environments remains a fundamental challenge in robotics, particularly in dynamic or expansive settings such as outdoor autonomous exploration. This task requires robust spatial reasoning and the ability to leverage prior experiences. While Large Language Models (LLMs) offer strong semantic capabilities, their application in embodied contexts is limited by a grounding gap in spatial reasoning and insufficient mechanisms for memory integration and decision consistency.To address these challenges, we propose GET (Goal-directed Exploration and Targeting), a framework that enhances object search by combining LLM-based reasoning with experience-guided exploration. At its core is DoUT (Diagram of Unified Thought), a reasoning module that facilitates real-time decision-making through a role-based feedback loop, integrating task-specific criteria and external memory. For repeated tasks, GET maintains a probabilistic task map based on a Gaussian Mixture Model, allowing for continual updates to object-location priors as environments evolve.Experiments conducted in real-world, large-scale environments demonstrate that GET improves search efficiency and robustness across multiple LLMs and task settings, significantly outperforming heuristic and LLM-only baselines. These results suggest that structured LLM integration provides a scalable and generalizable approach to embodied decision-making in complex environments.
NaviDiffusor: Cost-Guided Diffusion Model for Visual Navigation
Apr 14, 2025Visual navigation, a fundamental challenge in mobile robotics, demands versatile policies to handle diverse environments. Classical methods leverage geometric solutions to minimize specific costs, offering adaptability to new scenarios but are prone to system errors due to their multi-modular design and reliance on hand-crafted rules. Learning-based methods, while achieving high planning success rates, face difficulties in generalizing to unseen environments beyond the training data and often require extensive training. To address these limitations, we propose a hybrid approach that combines the strengths of learning-based methods and classical approaches for RGB-only visual navigation. Our method first trains a conditional diffusion model on diverse path-RGB observation pairs. During inference, it integrates the gradients of differentiable scene-specific and task-level costs, guiding the diffusion model to generate valid paths that meet the constraints. This approach alleviates the need for retraining, offering a plug-and-play solution. Extensive experiments in both indoor and outdoor settings, across simulated and real-world scenarios, demonstrate zero-shot transfer capability of our approach, achieving higher success rates and fewer collisions compared to baseline methods. Code will be released at https://github.com/SYSU-RoboticsLab/NaviD.
Prior Does Matter: Visual Navigation via Denoising Diffusion Bridge Models
Apr 14, 2025Recent advancements in diffusion-based imitation learning, which show impressive performance in modeling multimodal distributions and training stability, have led to substantial progress in various robot learning tasks. In visual navigation, previous diffusion-based policies typically generate action sequences by initiating from denoising Gaussian noise. However, the target action distribution often diverges significantly from Gaussian noise, leading to redundant denoising steps and increased learning complexity. Additionally, the sparsity of effective action distributions makes it challenging for the policy to generate accurate actions without guidance. To address these issues, we propose a novel, unified visual navigation framework leveraging the denoising diffusion bridge models named NaviBridger. This approach enables action generation by initiating from any informative prior actions, enhancing guidance and efficiency in the denoising process. We explore how diffusion bridges can enhance imitation learning in visual navigation tasks and further examine three source policies for generating prior actions. Extensive experiments in both simulated and real-world indoor and outdoor scenarios demonstrate that NaviBridger accelerates policy inference and outperforms the baselines in generating target action sequences. Code is available at https://github.com/hren20/NaiviBridger.